- 投稿日:2025/09/21
- 更新日:2025/10/05

🟩この記事の目的
ただの生成画像AIを試してみたという記事です。
いつもはChatGPTを使っているのですが、
他にも生成画像AIたくさんあるので、
同じプロンプトを突っ込んで、どのくらい違うんだろう?
と興味がわいたのでやってみました。
🟩対象の記事
私、noteをやっていて、記事に嫁様を題材にしたものがあります。
その記事のサムネイル画像をテーマに試してみました。
🟩使ったプロンプト
違いを試したいので、同じプロンプトを使います。
こんな感じのプロンプトを突っ込んでみます。
記事のストーリーから、「笑顔は『バレちゃったけど、ごまかしている』ような表情」を作り出してくれているかがポイントです。
#画像作成条件
-横長(1280×670)
-リアル寄りのイラスト。
-20代の日本人女性。天然っぽくて可愛い雰囲気。
-ロングヘアをポニーテールにしている。
-服装は部屋着風、ニットやスウェットのようなカジュアルスタイル。
-背景はパステルイエローの単色、グラデーションなし。
-上半身を描く(バストアップ)、左右に余白を大きくとる。
-色調は明るくポップ。
-女性は口元に手を当てて、ウインクしながら笑っている。
-その笑顔は「バレちゃったけど、笑ってごまかしている」表情。
-文字は入れない。
#あなたの役割
-あなたは世界一のプロのnoteサムネイルライターです。
-生成画像AIが理解しやすい英語にプロンプトを書き換えてください。
-上記の指示をもとに記事を読みたいと思える、かつ、誰でもわかりやすい、最高品質の画像を作ってください。
嫁様は20代ではないですけどね(笑)
ま、サムネイルなので。そこらへんはご容赦を。
英語版でも試してみます。
上記の指示を英語に直してもらいました。
日本語と英語で違いが出るかも試してみたかったんで。
Wide horizontal illustration (1280x670). A realistic-style drawing of a cute Japanese woman in her 20s with a natural, charming vibe. She has long hair tied in a ponytail. She is wearing casual loungewear, such as a knit sweater or sweatshirt. The background is a solid pastel yellow, no gradient. Draw her upper body (bust-up) with large empty space on the left and right sides. Use a bright and pop color tone. She is smiling playfully, holding her hand near her mouth, and winking. Her expression should feel like “I got caught, but I’m trying to cover it up.” No text in the image.
🟩試してみた生成画像AI
すいませんが、私の都合で、ChatGPTのみ有料版で試してみております。
▶️ChatGPT(Dalle3)
ChatGPT5、Autoのモデルで実施してみました。
 うんうん。指示通りですね。さすがChatGPT。
うんうん。指示通りですね。さすがChatGPT。
横幅サイズは3:2ですね。
処理時間はだいたい60秒くらい。うーん。って待つ感じの長さです。
▶️Gemini
GoogleさんのGeminiです。
モデルは2.5Flashを使います。

あれ?横長画像を指示したのに無視されますね。
英語プロンプトでは、手のしぐさも変わっています。
上半身(バストアップ)映してという指示だったので、
日本語は上半身を、英語は、バストアップを認識したのかもしれません。
処理時間はだいたい10秒くらい。早い!!!
▶️Canva
Canvaにも画像生成AIがくっついているようなのでやってみます。
マジック生成→画像→横方向に変更し、プロンプト入力
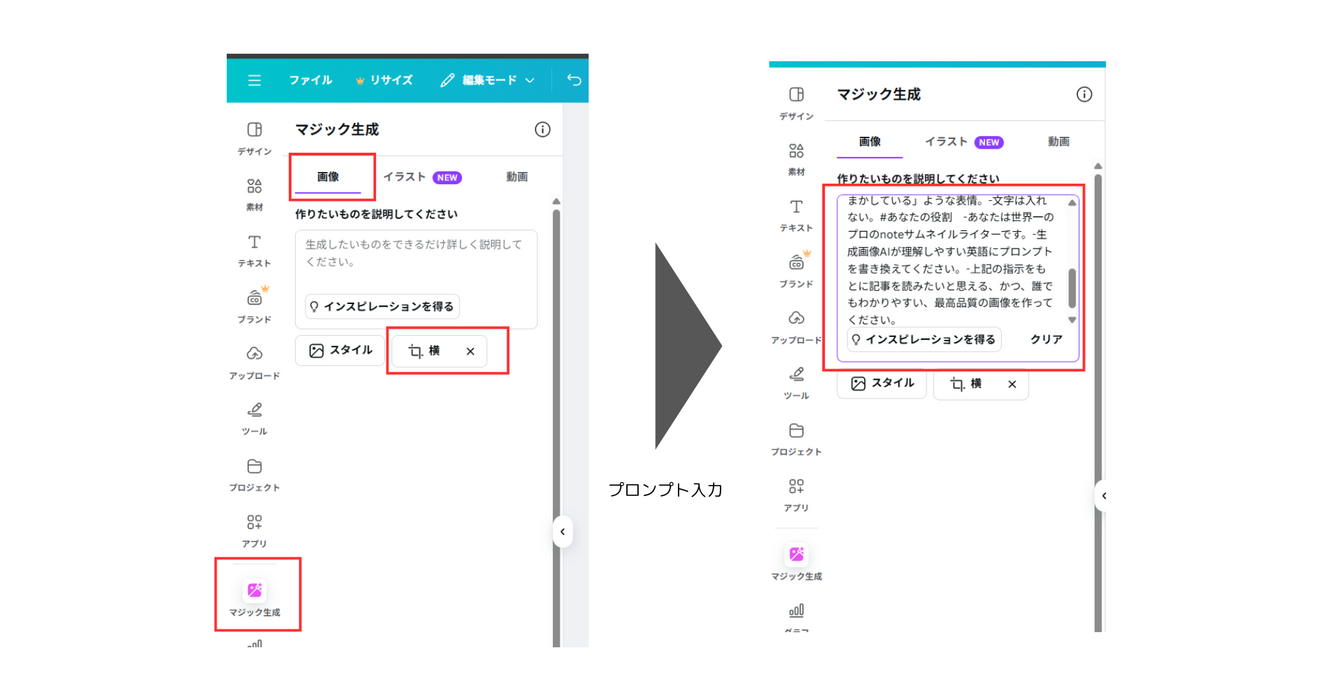
結果はこちら。

何も指示していないのに、4枚出してくれました。
しかも、ちょっとずつ画像を変えてくれています。
しかもだいぶ横長です。16:9で作ってくれました。
うーむ。Canvaおそろしや。
4枚出しても処理時間は日本語・英語ともに10秒程度。
Geminiと似てるなぁ。画像生成エンジンがGeminiと一緒なのかperplexityにきいてみたら、Dalle3系とのこと。ほんとかな。
Canvaの画像生成エンジンはGoogleのGeminiとは同じではありません。Canvaの画像生成AIはOpenAIのDALL·Eをベースにしていることが多く、GeminiはGoogleが開発した独自のマルチモーダルAIであり、画像生成モデルとしては「Imagen」など別の拡散モデル技術を使っています。両者は別系統の技術であり、CanvaはDALL·E系のAIを使い、GeminiはGoogle系のモデルを使っているため、基本的には異なるエンジンです。
10秒で作れるということは、ChatGPTも指示しだいでは、10秒程度で画像を作れるのだろうか?
▶️Bing Image Creator
MicroSoftが提供しているやつです。
どうもDalle3を使っているようです。
じゃあ、ChatGPTと近いのかな。
以下の設定でやってみます。枚数は変えられなかった。
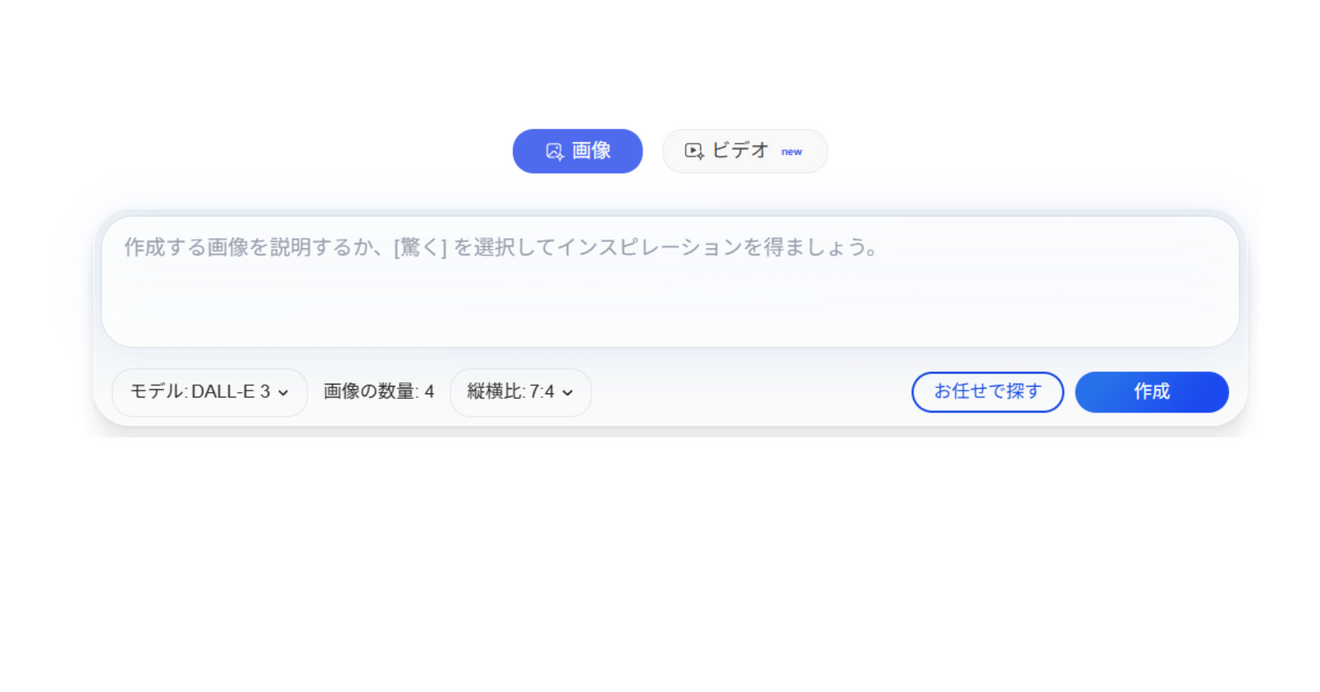
その結果がこちら

なぜか、日本語プロンプトは、ちょっぴりセクシーに、肩出し、下着チラ見えの画像に。。。
皆さまのお声:「(おい、何、サービス画像作ろうとしてんだ。おっさん。)」
いえ、決してそのような指示は出しておりません!!!
ど、ど、どうか信じてください。同じプロンプトです。
そして、「笑ってごまかしている要素」は完全に消え失せました。ただ、女の子が微笑んでいるだけです(笑)
英語プロンプトに至っては、2人出てきちゃった。
処理時間は24秒程度。まあ、そんなに長さは感じないかな。
▶️Stable Diffusion
次はStable Diffusionです。
スタイル:自由
アスペクト比:12:5
枚数:1枚(英語は2枚にしてみた)
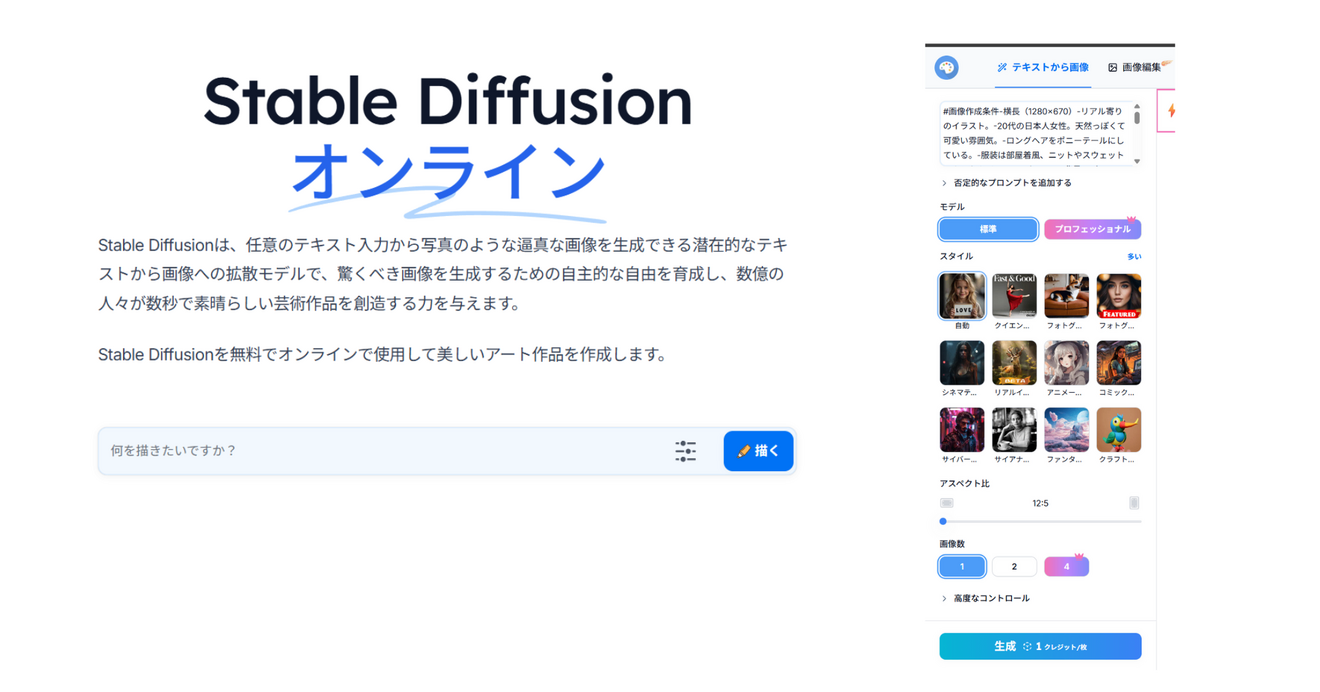
結果はこんな感じ

日本語は、背景にグラデーションが付いていた。
処理速度は、日本語が14秒、英語が21秒。多分2枚にしたからかな。
-女性は口元に手を当てて、ウインクしながら笑っている。
という指示が指くわえてるみたいな指示になっちゃってますね。
ちなみに気になったので生成エンジンについて、聞いてみた。
Stable Diffusionの画像エンジンは、「潜在拡散モデル(Latent Diffusion Model, LDM)」という技術に基づいています。これは、ノイズから少しずつ意味のある画像に変換していく「拡散モデル(Diffusion Model)」の一種です。技術的特徴ランダムなノイズ画像から、プロンプト(英語のテキスト指示)に従い少しずつノイズを除去しながら画像を生成画像の特徴を「潜在空間(Latent Space)」に圧縮し、高効率に学習・生成するAIモデルの中心にはニューラルネットワーク(U-Net等)と、画像とテキストを結び付けるエンコーダ(CLIP等)が利用されているまた、バージョンごとに細かい手法の違いもありますが、共通して「潜在拡散モデル」による画像生成がStable Diffusionのエンジンの核です。
だそうです。よくわからないですね。
▶️craiyon
あまり聞いたことのないAIでしたが、perplexityに聞いたら出てきたので試してみました。
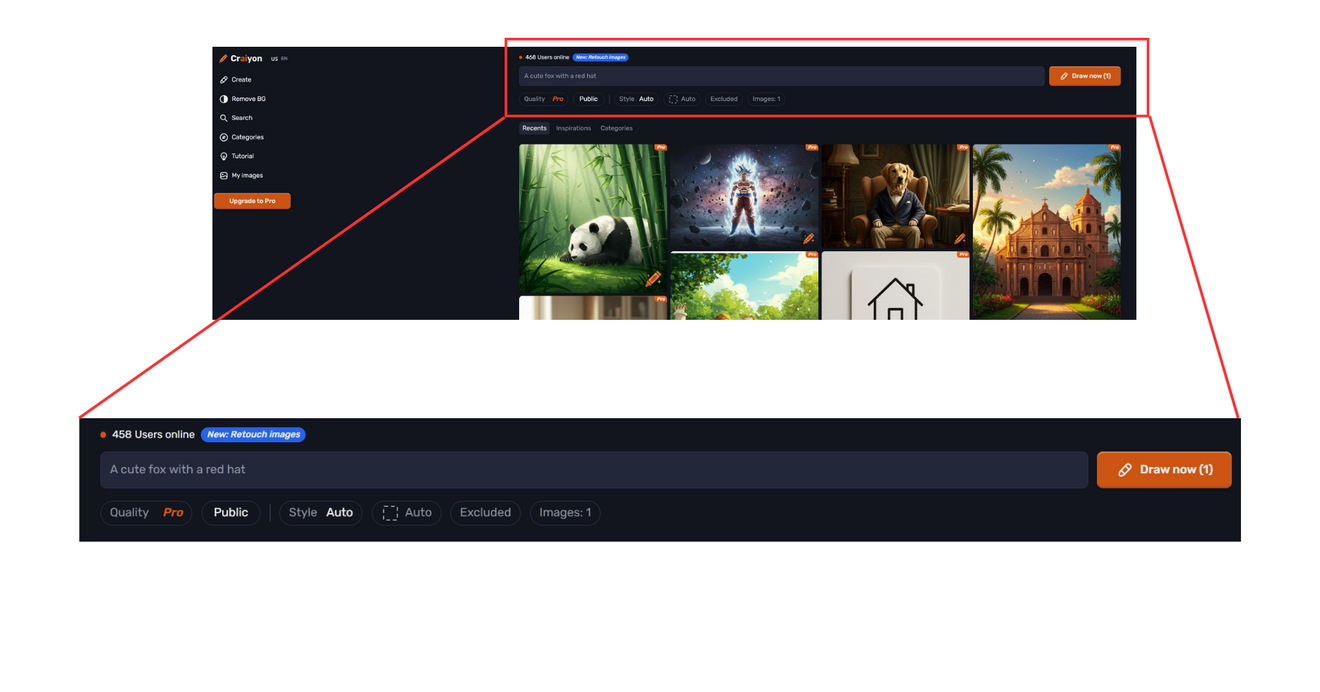
無料版では、枚数は1枚固定でした。アスペクト比も3種類から選べるみたいだけど、無料版は、Auto固定でした。
で、結果はというと

処理時間は日本語36秒、英語31秒でした。
おそらく、日本語を英語に変換する分時間がかかっているのでしょう。
英語に変換した分、指示の情報が抜け落ちているようです。手のしぐさは完全に抜け落ちています。
🟩まとめ
▶️比較してみた
いくつか試してみました。まとめるとこんな感じですね。
独断で〇×つけて表にしてみました。
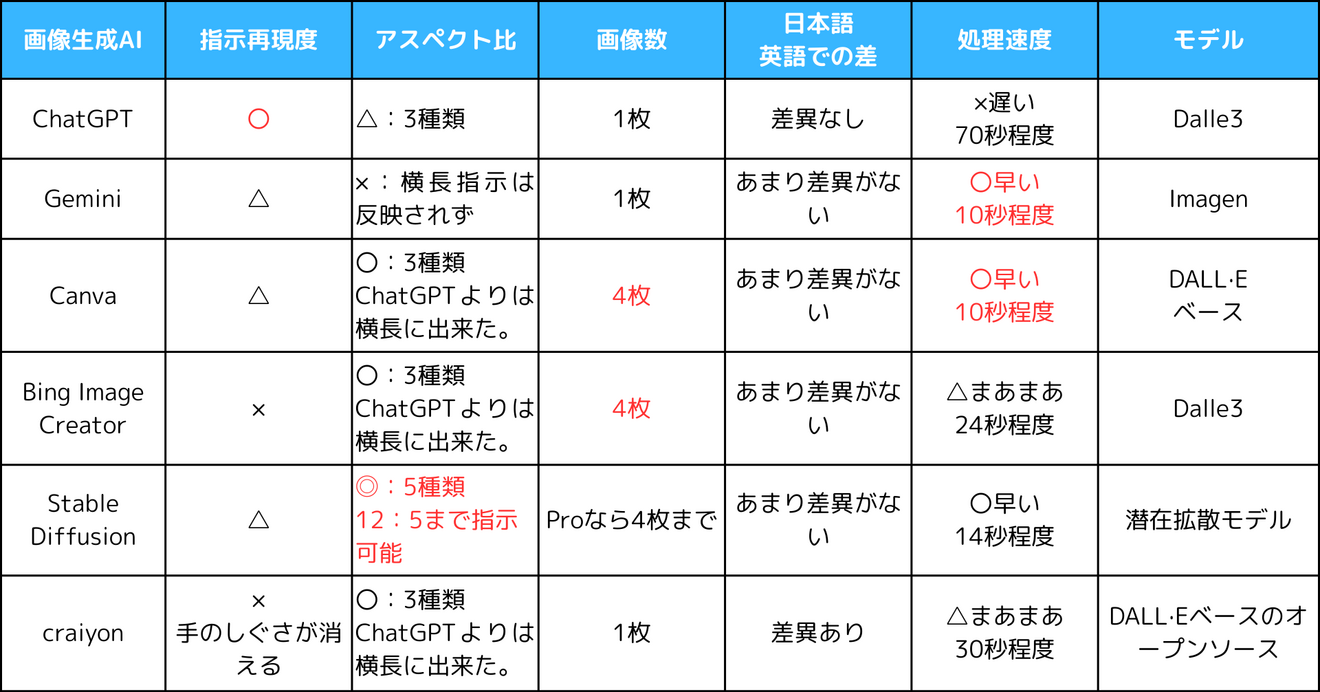
▶️使い方のアイデア
比較的に忠実に指示を守ってくれますが、やっぱり、ChatGPTはおそいですね。プロンプトをChatGPTで作ったからかもしれませんが。
noteのサムネイルを書くときどうしても横長に作れないので、困っていましたが、その点では、CanvaやStable Diffusionが良いかもしれません。
また、どんな画像が適切かイメージが付いていない場合は、
以下のように作ってみるのが良いかもしれません。
1.ChatGPTと相談しながら、書きたい画像の条件を作ってもらう。
2.BingやStableDiffusionで複数枚の画像を素早く作る。
3.そのイメージをChatGPTに入力して、画像を説明するプロンプトを作ってもらう。
4.3のプロンプトを微修正して、ChatGPTで画像を作る。
🟩最後に
いかがでしたでしょうか?
いろいろ試してみましたが、うまく使いこなす必要がありそうですね。
この記事が役に立てば幸いです。




